



快速入门
用一个简单的例子来示意,文本分类
安装
pip install transformers
示例——情感分析
以下均为python代码,我是放在jupyter中写的
from transformers import pipeline
pipe = pipeline("text-classification")
res = pipe("just so so!")
print(res)
# [{'label': 'POSITIVE', 'score': 0.9974353909492493}]
- 注意:
- pipeline() 方法指定任务和加载模型的,返回的对象可以用来做具体的事。
- pipe() 方法在此时传入的是你要分类的文本
- pipeline() 方法支持传入不同的参数,用来指定不同的任务,具体内容见下表。
- 在执行pipeline时,代码会自动从huggingface.co中下载模型到本地,这个例子中,使用的模型是distilbert-base-uncased-finetuned-sst-2-english。同时也可以自定义模型,只需要传入model参数即可。如果想从本地加载模型,可下载完模型后,直接填写本地模型地址,这个后续会提到。
pipeline中的参数值得是任务类型,可以传入如下类型。
| 任务 | 描述 | 模态 | Pipeline |
|---|---|---|---|
| 文本分类 | 为给定的文本序列分配一个标签 | NLP | pipeline(task=“text-classification”) |
| 文本生成 | 根据给定的提示生成文本 | NLP | pipeline(task=“text-generation”) |
| 命名实体识别 | 为序列里的每个token分配一个标签(人, 组织, 地址等等) | NLP | pipeline(task=“ner”) |
| 问答系统 | 通过给定的上下文和问题, 在文本中提取答案 | NLP | pipeline(task=“question-answering”) |
| 掩盖填充 | 预测出正确的在序列中被掩盖的token | NLP | pipeline(task=“fill-mask”) |
| 文本摘要 | 为文本序列或文档生成总结 | NLP | pipeline(task=“summarization”) |
| 文本翻译 | 将文本从一种语言翻译为另一种语言 | NLP | pipeline(task=“translation”) |
| 图像分类 | 为图像分配一个标签 | Computer vision | pipeline(task=“image-classification”) |
| 图像分割 | 为图像中每个独立的像素分配标签(支持语义、全景和实例分割) | Computer vision | pipeline(task=“image-segmentation”) |
| 目标检测 | 预测图像中目标对象的边界框和类别 | Computer vision | pipeline(task=“object-detection”) |
| 音频分类 | 给音频文件分配一个标签 | Audio | pipeline(task=“audio-classification”) |
| 自动语音识别 | 将音频文件中的语音提取为文本 | Audio | pipeline(task=“automatic-speech-recognition”) |
| 视觉问答 | 给定一个图像和一个问题,正确地回答有关图像的问题 | Multimodal | pipeline(task=“vqa”) |
| 文档问答 | 给定一个图像和一个问题,正确地回答有关文档的问题 | Multimodal | pipeline(task=“document-question-answering”) |
| 图像字幕 | 给定图像,生成标题 | Multimodal | pipeline(task=“image-to-text”) |
原理
接下来,我们分步来看一下这个pipeline() 方法做了哪些事。pipeline:顾名思义,流水线/管道的意思,就是让AI的调用像流水线一样简单。以上文中的文本分类为例,讲述整个pipeline的流程:
-
原理图
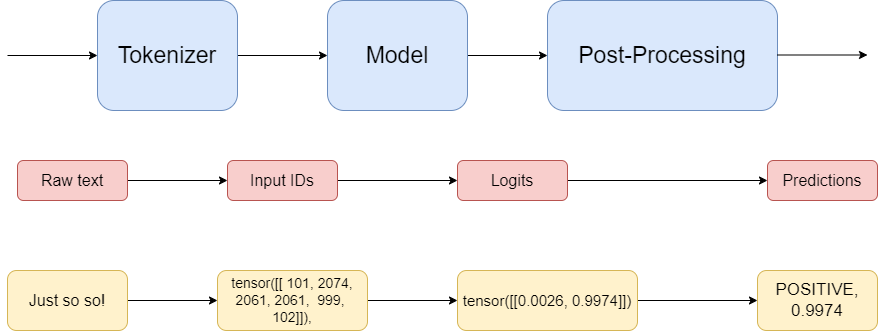
-
代码实现
from transformers import AutoTokenizer,AutoModel
import torch
# 加载分词器和模型,这里要指定从哪个模型加载分词器模型,使用上文提到的
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased-finetuned-sst-2-english")
model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased-finetuned-sst-2-english")
# 使用分词器对句子进行处理
seq = "just so so!"
input_text = "just so so!"
inputs = tokenizer(input_text, return_tensors="pt")
print(inputs)
# 输出结果如下 {'input_ids': tensor([[ 101, 2074, 2061, 2061, 999, 102]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1]])}
# 将分词结果传入model进行预测
res = model(**inputs)
# 对预测结果映射到二维(因为我们做的事二分类问题)
logits = torch.softmax(res.logits, dim=-1)
print(logits) # tensor([[0.0026, 0.9974]])
pred = torch.argmax(logits).item()
print(pred) # 1
# 此时输出的pred为0或者1,需要进行映射,才能返回之前返回的 'label': 'POSITIVE'
# 查看一下model的配置id2label,可以发现1就是POSITIVE。当然就可以自定义这个配置的
print(model.config.id2label)
# {0: 'NEGATIVE', 1: 'POSITIVE'}
#映射输出
result = model.config.id2label.get(pred)
print(result) # POSITIVE
print(float(logits[0][1])) # 0.9974353909492493
评论区