



Transformers学习之Datasets 组件
一、说明
- 用途:Datesets 顾名思义就是用来加载和保存数据集的组件
二、加载Huggingface数据集
- 选择数据集
如下图,你可以在对应位置选择你想要的数据集,选择任务和语言后,右边会出现对应的数据集
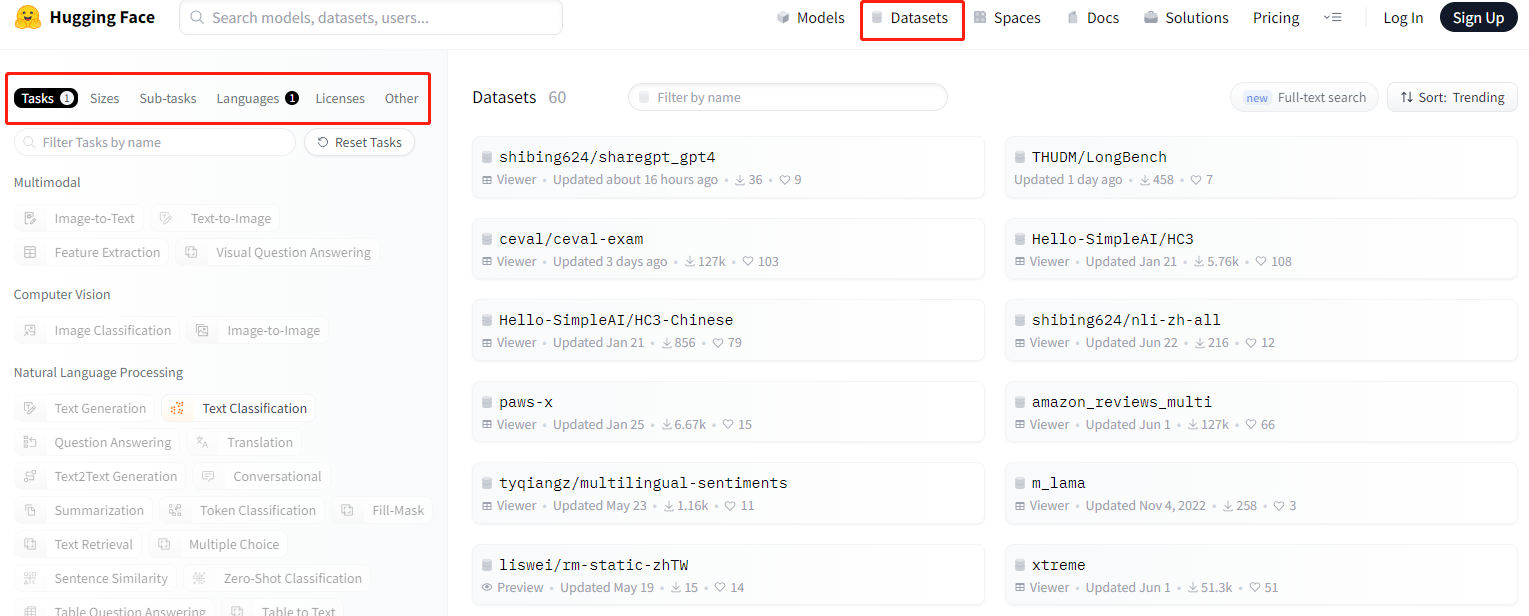 点进去对应的数据集,可以看到预览整个数据集,然后点击复制按钮就可以加载数据集了。
点进去对应的数据集,可以看到预览整个数据集,然后点击复制按钮就可以加载数据集了。
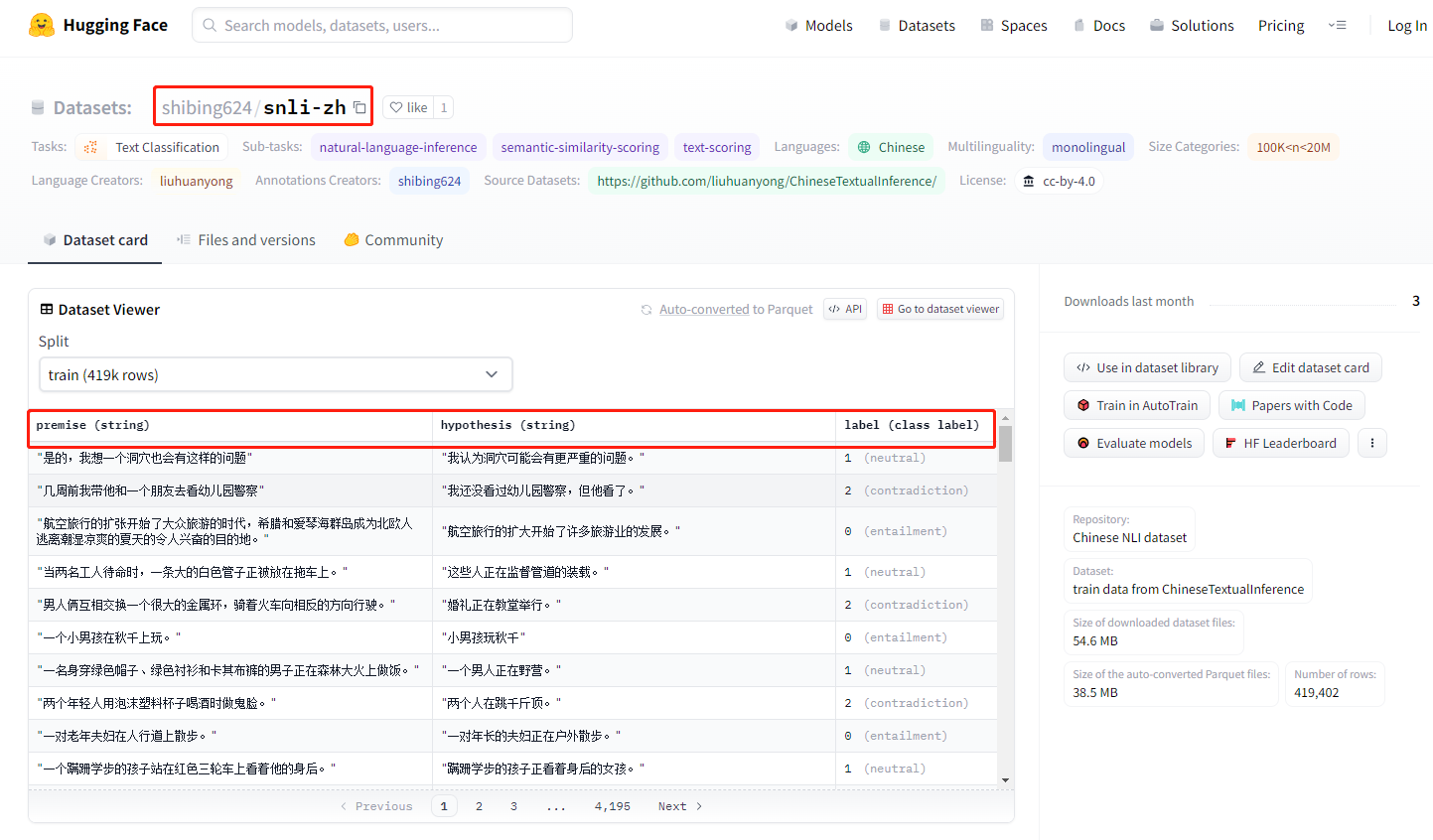
- 加载数据集
from datasets import *
datasets = load_dataset("shibing624/snli-zh")
print(datasets)
输出结果如下,可以看到整个数据集的配置:只有一个训练集集,一共有419402条数据,每条数据包含三个字段。
DatasetDict({
train: Dataset({
features: ['premise', 'hypothesis', 'label'],
num_rows: 419402
})
})
三、加载本地数据集
加载本地数据集,支持多种格式,在官方文档里提到的方式有 **JSON, CSV, Parquet, text等
加载csv文件
-
csv文件示例
label review 1 很快,好吃,味道足,量大 1 没有送水没有送水没有送水 1 非常快,态度好。 1 方便,快捷,味道可口,快递给力 1 菜味道很棒!送餐很及时! -
加载数据集
dataset = load_dataset("csv", data_files="./waimai_10k.csv")
print(dataset)
- 会把csv文件加载成为训练集
DatasetDict({
train: Dataset({
features: ['label', 'review'],
num_rows: 11987
})
})
加载JSON文件
dataset = Dataset.from_json("./waimai_10k.json")
dataset
从pandas加载
import pandas as pd
data = pd.read_csv("./waimai_10k.csv")
dataset = Dataset.from_pandas(data)
从其他方式加载
官方支持从如下方式加载,如有需要,可以查阅资料。
def from_file()
def from_buffer()
def from_pandas()
def from_dict()
def from_list()
def from_csv()
def from_generator()
def from_json()
def from_parquet()
def from_text()
def from_spark()
def from_sql()
自定义脚本加载
可以自己写一个继承datasets.GeneratorBasedBuilder 的类文件,就可以进行自己加载了。
四、操作数据集
查看数据集
datasets = load_dataset("csv", data_files="./waimai_10k.csv")
datasets["train"][0]
# {'label': 1, 'review': '很快,好吃,味道足,量大'}
datasets["train"].column_names
# ['label', 'review']
datasets["train"].features
#{'label': Value(dtype='int64', id=None),'review': Value(dtype='string', id=None)}
拆分数据集
把数据集按照一定规则进行拆分,形成训练集,测试集
# 不拆分
datasets = load_dataset("csv", data_files="./waimai_10k.csv")
# 按切片拆分
dataset = load_dataset("csv", data_files="./waimai_10k.csv", split="train[:100]")
# 按比例拆分
dataset = load_dataset("csv", data_files="./waimai_10k.csv",, split=["train[:50%]")
划分数据集
datasets = load_dataset("shibing624/snli-zh")
这是划分前数据集,只有训练集
DatasetDict({
train: Dataset({
features: ['premise', 'hypothesis', 'label'],
num_rows: 419402
})
})
按比例划分一个测试集
dataset = datasets["train"]
datasets.train_test_split(test_size=0.5)
划分后
DatasetDict({
train: Dataset({
features: ['premise', 'hypothesis', 'label'],
num_rows: 377461
})
test: Dataset({
features: ['premise', 'hypothesis', 'label'],
num_rows: 41941
})
})
保存数据集
# 保存
datasets.save_to_disk("./processed_data")
# 加载
processed_datasets = load_from_disk("./processed_data")
评论区