



本文是带你手把手对预训练模型进行继续训练。
预训练模型分类
对于什么预训练模型,以及预训练模型的由来,可以参考知乎上的“请问深度学习中预训练模型是指什么?如何得到?”,一个比一个好。本文主要是以代码的角度进行解析如何与对这些预训练模型进行继续训练。 目前预训练模型的分类以及适用任务:
- 序列到序列(Transformer):机器翻译,阅读理解,文本生成任务,文本摘要
- 因果语言模型(Causal Language Model, CLM):文本生成任务
- 掩码语言模型(Masked Language Model, MLM):自然语言理解,如:信息抽取,完型填空,情感分析等
- 前缀语言模型(Prefix language model):文本生成任务,文本摘要
预训练模型详解
序列到序列模型
序列到序列模型,其实就是Encoder-Decoder模型,也就是最简单的Transformer架构。 Encoder 部分是 Masked Multi-Head Self-Attention,Decoder 部分是 Casual Multi-Head Cross-Attention 和 Casual Multi-Head Self-Attention 兼具。比如T5,BART,MASS等。
案例
因果语言模型
即Transformer的Decoder,比如GPT。也叫自回归语言模型(Auto-Regressive Language Models)。这里的因果可以理解为下一个token是当前token的果,也就是基于当前token预测下一个token。因此这种模型在NLG(自然语言生成) 任务上表现很好,目前的LLM大都是这种类型的。数据的具体表现如下图:
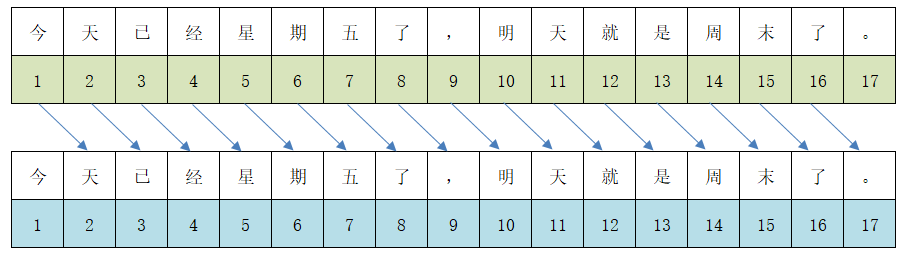 在数据处理部分(参考之前内容Transformers框架之分词器(Tokenizer)学习),就是要将当前token的label设置成下一个token的编码。
在数据处理部分(参考之前内容Transformers框架之分词器(Tokenizer)学习),就是要将当前token的label设置成下一个token的编码。
案例
- 利用资治通鉴翻译(白话文)来简单训练一下模型,然后做一个文本生成的功能。
- 选用的模型是一个因果关系模型bloom-560m
# 因果语言模型训练实例
from datasets import load_dataset, Dataset
from transformers import AutoTokenizer, AutoModelForCausalLM, DataCollatorForLanguageModeling, TrainingArguments, Trainer, BloomForCausalLM
## 加载数据集
with open('短篇章和资治通鉴翻译.txt','r') as f:
lines = f.readlines()
contents=[{'content':line.replace("\n","")} for line in lines]
da=Dataset.from_list(contents[:100000])
tokenizer = AutoTokenizer.from_pretrained("/data1/model/history/bloom-560m")
def process_func(examples):
contents = [e + tokenizer.eos_token for e in examples["content"]]
return tokenizer(contents, max_length=128, truncation=True)
tokenized_da = da.map(process_func, batched=True, remove_columns=da.column_names)
from torch.utils.data import DataLoader
dl = DataLoader(tokenized_da, batch_size=2, collate_fn=DataCollatorForLanguageModeling(tokenizer, mlm=False))
model = AutoModelForCausalLM.from_pretrained("/data1/model/history/bloom-560m")
## 配置训练参数
args = TrainingArguments(
output_dir="./causal_lm",
per_device_train_batch_size=32,
gradient_accumulation_steps=8,
logging_steps=50,
num_train_epochs=1
)
## 创建训练器
trainer = Trainer(
args=args,
model=model,
train_dataset=tokenized_da,
data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False)
)
## 模型训练
trainer.train()
以下是模型推理结果:
## 模型推理
from transformers import pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer, device=0)
pipe("狡兔死,走狗烹;飞鸟尽,良弓", max_length=128, do_sample=True)
# [{'generated_text': '狡兔死,走狗烹;飞鸟尽,良弓尽。'}]
pipe("勿以善小而不为,", max_length=128, do_sample=True)
# [{'generated_text': '勿以善小而不为,勿以恶小而为之,这是道;'}]
掩码语言模型
即Transformer的Encoder,相比自回归模型,自编码模型的学习过程,能看到待预测词的前后内容,所以对文本的理解是更深入的,在同等成本的情况下理论上自编码模型对文本的分类、回归方面的 NLU(自然语言理解)等问题 会有更好性能表现。典型的自编码模型有 BERT、ERNIE、ALBERT、RoBERTa、DistilBERT、ConvBERT、XLM、XLM-RoBERTa、FlauBERT、ELECTRA、Funnel Transformer。 掩码语言模型,顾名思义,就是对文本中的数据进行掩蔽,然后利用语言模型进行预测出该掩蔽位置的编码。如下示例中,对于“五”这个字利用[MASK]掩蔽,模型最终输出的对应位置的字为"五"。
输入:"今天已经星期[MASK]了,明天就是周末了。"
输出:"今天已经星期五了,明天就是周末了。"
在数据处理部分,对于label而言,利用tokenizer处理完的数据大致如下:
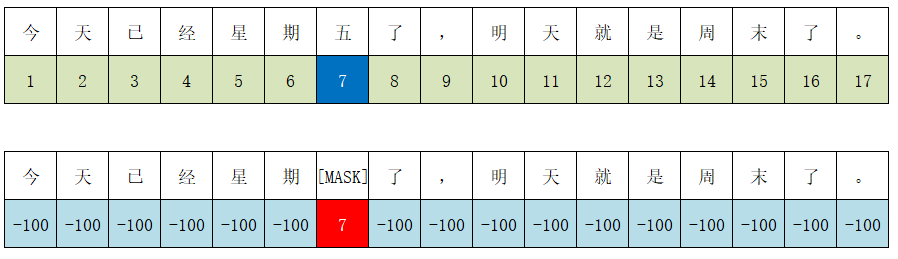
数据处理示例
简单的数据处理的代码如下:
import numpy as np
import random
ss="上必且劝之以赏,然后可进"
random_idx=random.sample(range(len(ss)),k=2)
ss_li=list(ss)
for i in random_idx:
ss_li[i]='[MASK]'
print(''.join(ss_li))
# 上必且劝之以赏[MASK]然后可[MASK]
案例
- 利用资治通鉴原文(文言文)来简单训练一下模型,然后做一个掩码预测的功能。
- 选用的模型是一个古汉语的sikubert
from datasets import load_dataset, Dataset
from transformers import AutoTokenizer, AutoModelForMaskedLM, DataCollatorForLanguageModeling, TrainingArguments, Trainer
# 读取文件
with open('资治通鉴-古文.txt','r') as f:
lines = f.readlines()
contents=[{'content':line.replace("\n","")} for line in lines]
ds=Dataset.from_list(contents)
tokenizer = AutoTokenizer.from_pretrained("/data1/model/history/sikubert")
def process_func(examples):
return tokenizer(examples["content"], max_length=128, truncation=True)
tokenized_ds = ds.map(process_func, batched=True, remove_columns=ds.column_names)
tokenized_ds
from torch.utils.data import DataLoader
dl = DataLoader(tokenized_ds, batch_size=2, collate_fn=DataCollatorForLanguageModeling(tokenizer, mlm=True, mlm_probability=0.15))
## 创建模型
model = AutoModelForMaskedLM.from_pretrained("/data1/model/history/sikubert")
## 配置训练参数
args = TrainingArguments(
output_dir="./masked_lm",
per_device_train_batch_size=128,
logging_steps=50,
num_train_epochs=1
)
## 创建训练器
trainer = Trainer(
args=args,
model=model,
train_dataset=tokenized_ds,
data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=True, mlm_probability=0.15)
)
## 模型训练
trainer.train()
## 模型推理
from transformers import pipeline
pipe = pipeline("fill-mask", model=model, tokenizer=tokenizer, device=0)
res =pipe("撒盐空中差可拟,未若柳絮因[MASK]起")
res_tuple=[]
for i in res:
res_tuple.append((i['score'],i['token_str'],i['sequence'].replace(' ','')))
sorted(res_tuple,reverse=True)
使用模型对句子 “撒盐空中差可拟,未若柳絮因[MASK]起” 中的MASK位置进行预测,输出结果如下
[(0.26318901777267456, '风', '撒盐空中差可拟,未若柳絮因风起'),
(0.1423548460006714, '之', '撒盐空中差可拟,未若柳絮因之起'),
(0.025364428758621216, '此', '撒盐空中差可拟,未若柳絮因此起'),
(0.02507396787405014, '他', '撒盐空中差可拟,未若柳絮因他起'),
(0.02496611699461937, '而', '撒盐空中差可拟,未若柳絮因而起')]
数据中的第一列是分数,可以看出,选择 风 的概率会大很多。
前缀语言模型
前缀语言模型,英文为Prefix language model,常见模型有UniLM、GLM等。与自回归语言模型相比,前缀语言模型在抽取输入文本特征时用了 Fully-Visible Mask(Encoder 用的掩码,能看到「过去」和「未来」)而不是 Future Mask(Decoder 用的掩码,只能看到「过去」),而生成本文部分则与自回归语言模型一样,只看到左侧。
案例
附录
- 代码地址: https://github.com/Lyn4ever29/transformers-learning
- 微信公众号 codeCraft编程工艺

评论区