



如何安装Hive请参考Hadoop生态系统—数据仓库Hive的安装, 更多大数据相关教程小鱼吃猫的大数据学习笔记
一、Hive内部表操作
- 创建数据库
create database test;
use test;
后续操作都会在这个database中,创建完数据库后。可以在hdfs的WebUI中看到存储的数据库,后边每执行一句sql,可以及时在这里看到变化
2.创建表
-- 创建表,row format是指定文件之间用,分隔
CREATE TABLE t_user (id int,name string,age int) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
- 添加数据
Hive中添加数据时不使用INSERT这种语句进行一条一条添加,直接将数据文件复制到对应的目录上即可。当前t_user数据库在hdfs中的目录是:/user/hive/warehouse/test.db/t_user。我们在当前目录下创建一个t_user.txt文件,内容如下(里边就是对应的表数据,类似于csv这种文本):
1,张三,18
2,李四,20
3,王五,24
4,老六,48
执行如下命令进行文件复制(不要在hive命令行中执行):
hadoop fs -put /home/t_user.txt /user/hive/warehouse/test.db/t_user
- 在hive中读取数据,执行结果如下图
hive> select * from t_user;
OK
1 张三 18
2 李四 20
3 王五 24
4 老六 48
Time taken: 0.276 seconds, Fetched: 4 row(s)
二、Hive外部表操作
- 创建一个数据文件students.txt,将把它放到hdfs的其他目录下,如/tmp目录下
hadoop fs -put /home/students.txt /tmp
- 利用上边的文件创建一个新的数据库
create external table student_ext (Sno int,Sname string,Sex string,Sage int,Sdept string) row format delimited fields terminated by ',' location '/tmp/students';
- 然后执行查询sql
select * from students;
注意:
在删除内部表的时候,drop table t_user时,会直接删除hdfs中表的文件夹,其中的数据文件也会被删除。
在删除外部表的时候,drop table students时,只会删除表,不会删除源数据文件。
三、Hive分区表操作
这里的分区其实就是对数据文件进行分目录存储,在WHERE查询时可以指定分区,然后提高查询效率。主要有两种分区:普通分区和动态分区。
3.1 普通分区
有两个文件user_u.txt和user_c.txt代表了两个国家的人。以国家进行分区
---user_u.txt
1,Tom
2,Jerry
---user_c.txt
1,张三
2,李四
- 创建表
create table t_user_p (id int,name string) partitioned by (country string) row format delimited fields terminated by ',';
- 往表中加载数据
此时加载数据时不能使用之前通过复制数据文件的方式,要用LOAD DATA命令,格式如下
LOAD DATA [LOCAT] INPATH 'filepath' [OVERWRITE] INTO TABLE table_name [PARTITION (partcol1=val1,partcol2=val2...)]
其中filepath 是主机上数据文件的位置,overwrite 覆盖已有数据。在本例子中,命令如下:
load data local inpath '/home/t_user_u.txt' into table t_user_p partition(country='USA');
load data local inpath '/home/t_user_c.txt' into table t_user_p partition(country='CHINA');
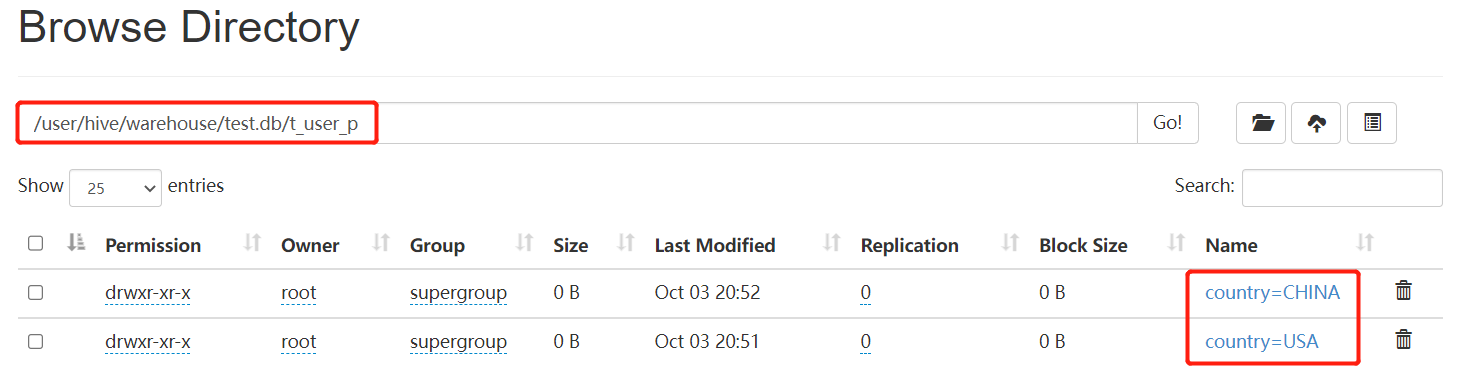
结果如下:
hive> select * from t_user_p;
OK
1 张三 CHINA
2 李四 CHINA
1 Tom USA
2 Jerry USA
Time taken: 0.401 seconds, Fetched: 4 row(s)
在HDFS上存储的文件如下:
- 修改分区的命令
-- 修改CHINA分区为JAPAN
ALERT TABLE t_user_p PARTITION (country='CHINA') RENAME TO PARTITION (country='JAPAN');
-- 删除JAPAN分区
ALERT TABLE t_user_p DROP IF EXISTS PARTITION (country='JAPAN');
3.2 动态分区
动态分区区别于普通分区的最大点就是不需要提前创建如USA、CHINA、JAPAN这种分区。一个用途就是根据字段自动创建分区。支持把旧表的数据通过select查询出来然后放到新的表中,以下例子就是按照月份和日期统计网站访问ip的操作
- 开户Hive动态分区功能
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
- 创建数据文件view_log.txt
2021-10-18,ip1,index
2021-10-19,ip1,second
2021-10-19,ip1,index
2021-10-19,ip2,second
2021-11-18,ip1,second
2021-11-18,ip3,index
2021-11-18,ip4,index
2021-11-18,ip4,second
- 创建原始表,并载入数据
-- 创建表
create table web_log(day string,ip string,path string) row format delimited fields terminated by ",";
-- 加载数据
load data local inpath '/home/view_log.txt' into table web_log;
- 创建目标表
-- 按月/日期分析表
create table web_log_md (ip string,path string) partitioned by (month string,day string);
- 动态插入数据到目标表中
insert overwrite table web_log_md partition(month,day) select ip,path,substr(day,1,7) as month,day from web_log;
- 使用如下命令查看目标表中的分区数据
show partitions web_log_md;
四、Hive桶表操作
为了将表进行更细粒度的划分,可以创建桶表。所谓的桶表就是根据某个属性字段把数据分成几个桶(默认值是-1),跟MySQL中的水平分表(按数据分)相似,上边的分区跟垂直分表差不多(按字段分)。
- 开启分桶功能
hive> set hive.enforce.bucketing=true;
# HQL最终都会转换成MR程序,所以分桶数要与ReduceTask数保护一致
hive> set mapreduce.job.reduces=4;
- 创建桶表
CREATE TABLE student_buck(Sno int,Sname string,Sex string,Sage int,Sdept string) CLUSTERED BY (Sno) into 4 buckets row format delimited fields terminated by ',';
- 创建临时表用以加载数据
无法直接将数据加载到桶表中,所以需要先创建一个临时表
CREATE TABLE student_buck_tmp(Sno int,Sname string,Sex string,Sage int,Sdept string) row format delimited fields terminated by ',';
- 加载数据到临时表中
load data local inpath '/home/students.txt' into table student_buck_tmp;
- 加载数据到桶表中
insert overwrite table student_buck select * from student_buck_tmp cluster by (Sno);
- 删除临时表
drop table student_buck_tmp;
- 查询数据
select * from student_buck;
然后在hdfs中就可以看到sutdent_buck目录下是有4个桶的
五、Hive数据操作
主要操作与MySQL是一样的,区分主要有以下几点
- 聚合函数,如sum,avg等一般与group by 一起使用
- sort by 表示的是reduce内部排序
- distribute by 表示的是整体排序,与sort by 一起使用
- cluster by 表示的是分桶查询语句
评论区