



一、数据仓库
数据仓库是一个面向主题的、集成的、随时间变化,但信息本身相对稳定的数据集合,相比于传统型数据库,它主要用于支持企业或组织的决策分析处理。主要有以下3个特点:
-
数据仓库是面向主题的:
数据仓库中的数据是按照一定的主题域进行组织,大概意思就是说存的数据是一类数据
-
数据仓库是随时间变化的:
其中存的数据是有时序的,会保存很长一段时间的数据
-
数据仓库相对稳定:
数据仓库主要是用来进行数据的查询,很少进行修改和删除
数据仓库的结构

二、Hive简介
2.1 Hive简介
Hive最初是Facebook开发的一款用来SQL分析的应用,它是建立在Hadoop文件系统上的数据仓库,能够对存储在HDFS中的数据进行数据提取、转换和加载(ETL),这是一种可以存储、查询、分析存储在Hadoop中的大规模数据的机制。Hive定义了简单的类SQL查询语言,简称HQL。但Hive并不是一个数据库,它只是提供了和数据库相类似的查询语言。其实他是用来执行简化MapReduce操作的,可以解决很多MapReduce解决起来比较麻烦的事。Hive把用户的HiveQL语句解释转换为MapReduce作业提交到Hadoop集群上,Hadoop监控作业执行过程,然后返回作业执行结果给用户。
2.2 Hive系统架构
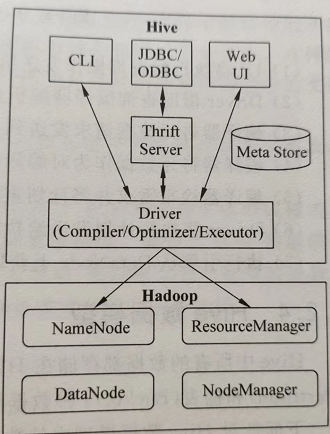
- 用户接口:主要分为3个,分别是CLI(命令行)、JDBC/ODBC(由Java实现的用来连接数据库)、和WebUI(浏览器)。
- 跨语言服务(Thrift Server):Thrift是Facebook开发的一个软件框架,用来进行可扩展且跨语言的服务,Hive集成该服务,可以让不同的编程语言调用Hive的接口
- 底层的驱动引擎:主要包含编译器(Compile)/优化器(Optimizer)/执行器(Executor)
- 元数据存储系统(Metastore):Hive的元数据包括表名、列、分区及其相关属性,表数据所在目录的位置信息,Metastore默认存在自带的Derby数据库中(这是一个嵌入式数据库,更多有关嵌入式数据库资料查看这里在Spring中使用嵌入式数据库-H2)。
三、Hive实践
3.1 Hive安装
由于Hive依赖于Hadoop,所以要提前安装Hadoop,参见手把手教你安装Hadoop集群
-
下载并解压
之前的Hadoop是分布式安装在3台机器上的,但Hive只需要安装在一台机子即可,我这里选择的是hadoop02
下载地址:https://hive.apache.org/downloads.html,(在国内镜像网站上也是可以下载的)注意与Hadoop的版本对应,之前安装的Hadoop是2.x版本,这里下载安装Hive 2.3.9。 具体版本对应关系可在下载页面查看。
tar zxvf apache-hive-2.3.9-bin.tar.gz
-
配置环境变量
如何配置Linux环境变量
# ---------Hive----------
export HIVE_HOME=/home/apache-hive-2.3.9-bin
export PATH=$HIVE_HOME/bin:$HIVE_HOME/conf:$PATH
-
修改配置文件
这一步不是必须的,也就是不修改配置文件也是可以启动的。
Hive默认的配置是使得Derby数据库进行存储的,是单用户的模式,也就是意味着同一时间只能有一个用户使用Hive。这里修改的配置主要是使用MySQL来存储元数据。在Hive配置中原本有hive-default.xml.template,对这个文件进行复制修改
cd $HIVE_HOME/conf
cp hive-default.xml.template hive-site.xml
修改如下内容,可根据name属性进行搜索,可能并不连续
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.83.1:3307/hive?createDatabaseIfNotExist=true</value>
<description>
Mysql连接地址
</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>mysql密码</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
<description>JDBC驱动</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>mysql用户名</description>
</property>
<property>
<name>hive.querylog.location</name>
<value>/data/hive/querylog</value>
<description>Location of Hive run time structured log file</description>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/data/hive/scratchdir</value>
<description>Local scratch space for Hive jobs</description>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/data/hive/resourcesdir</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>
<property>
<name>hive.server2.logging.operation.log.location</name>
<value>/data/hive/operation_logs</value>
<description>Top level directory where operation logs are stored if logging functionality is enabled</description>
</property>
-
将Mysql的JDBC连接连接驱动放进hive的lib目录下,注意下载与Mysql对应的版本
-
在Mysql中创建hive数据库,并在hive的bin下执行如下命令,初始化Mysql中元数据的存储schema
./schematool -initSchema -dbType mysql
-
启动Hive
由于已经配置了环境变量,所以直接执行hive即可启动
评论区